
Use Case
- Home
- Fraud Detection
Uses Cases:
Fraud Detection
Fraud is a financial drain, a risk for businesses and consumers alike. With fraud attempts skyrocketing, how can you identify fraud in time to stop it? Graph-based approaches to detecting fraud analyze complex linkages between people, transactions, and institutions. Peruri Graph Analytics effectively reveals patterns of fraud and surfaces anomalies.

What will You Do

Discover how a top fintech company reduces manual investigation and finds more fraud

Learn three flexible techniques for detecting shifting fraud patterns

Find out which graph algorithms to run – and why
See a sample graph data model
Introduction
In the face of fraud challenges in the digital era, fraud detection is becoming increasingly important for maintaining data security and electronic transactions. Credit card fraud is a growing issue with the widespread use of credit cards in financial transactions. Fraudsters are always looking for ways to steal credit card information and use it for personal gain. One way to combat credit card fraud is by using graph algorithms. Graph algorithms can be used to model credit card transaction networks and detect unusual patterns that may indicate fraud.
In this section, we will explore and introduce the Credit Card dataset. From the key entities to the relationships between them, this dataset provides a strong foundation for developing various analytics solutions, including the creation of a fraud detection system. Let us understand the characteristics of this dataset, and how the information contained in it can be a valuable source of knowledge for decision-making and business strategy development.
Dataset
The credit card dataset used is a dataset that models financial transactions using graphs. The main entities in this dataset are customers and merchants. Customers are represented by nodes labeled Person, while merchants are represented by nodes labeled Merchant. The relationship between a customer and a merchant is represented by the HAS_BOUGHT_AT directed relation. This relation indicates that a customer has purchased at a particular merchant.
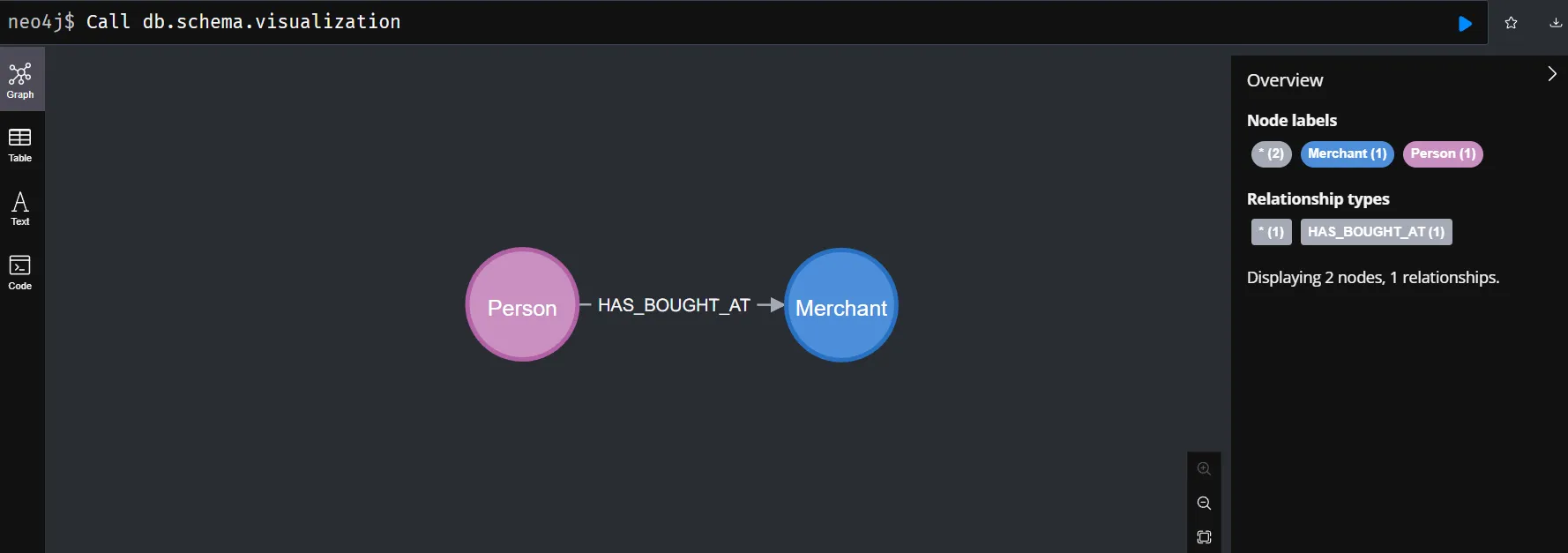
Nodes
This dataset has two main node types: Person (Customer) and Merchant. Each node has attributes that provide information about that entity.
- • Person
- id (string): Unique ID of the customer. Used to distinguish between customers.
- name (string): The name of the customer.
- gender (string): The gender of the customer ("man" or "woman").
- age (string): The age of the customer.
- • Merchant
- id (string): Unique ID of the merchant. Used to distinguish between merchants.
- name (string): The name of the merchant.
- street (string): The street address of the merchant.
Relationships
This dataset has only one relationship type, HAS_BOUGHT_AT. This relationship connects the Person node with the Merchant node and indicates that a customer has purchased at a particular merchant. This relationship has attributes that provide more detailed information about the transaction.
- • HAS_BOUGHT_AT
- amount (number): Purchase amount in USD.
- time (string): Purchase time in a specific format (e.g. "YYYY/MM/DD").
An example of using the HAS_BOUGHT_AT relation:
Nodes and Relationship in Credit Card Transactions Graph
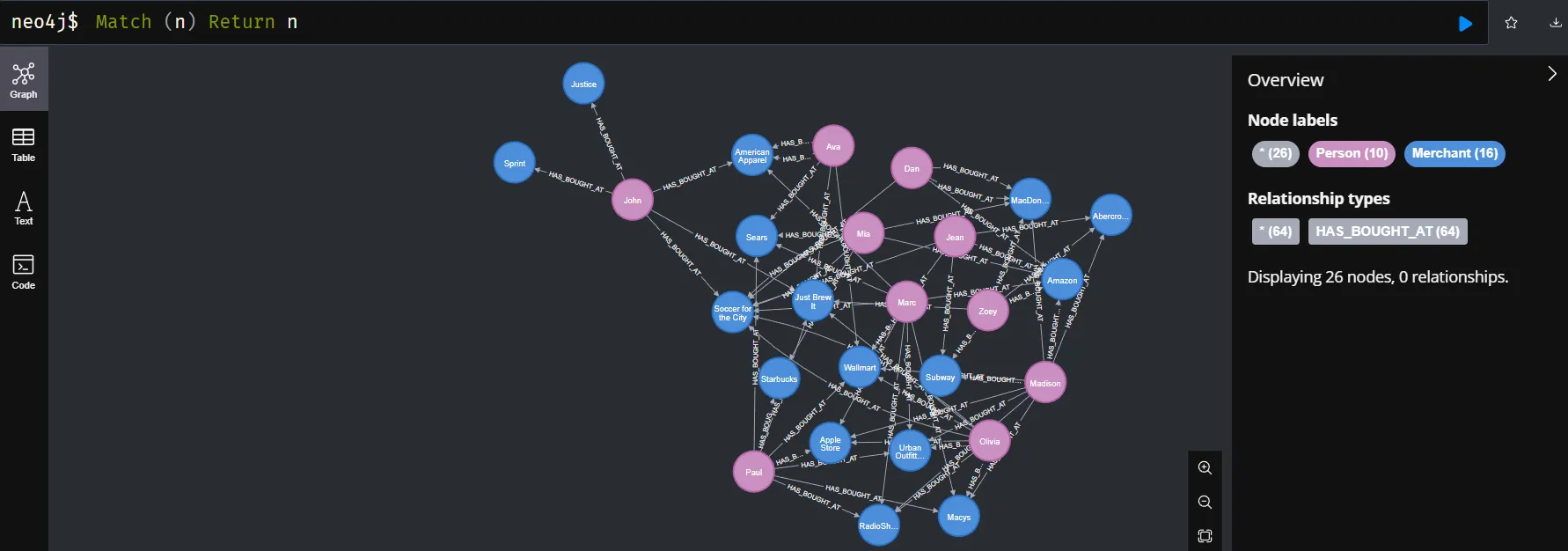
The result of this query will contain all paths that satisfy the defined graph pattern, which consists of nodes and relations connected through the relations :HAS_BOUGHT_AT. Each path in the result will include all the nodes and relations involved in the pattern.
- Person and Merchant:
- Person node represents the customer involved in the transaction.
- [:HAS_BOUGHT_AT] connects customers with the merchant where they did the transaction.
- Merchant node represents the place where they did the transaction.
Data Preparation
In exploring the Credit Card dataset, data preparation is a crucial step to understanding the relationships between key entities. In this section, we will enter the Data Preparation stage, where we will create two important nodes, namely the Person node and the Merchant node. These nodes will be the foundation for understanding the dynamics of the relationship between customers and merchants in the Credit Card dataset environment. With the creation of the nodes and the relationship between them, we will have a strong foundation to explore and analyze the business interactions within the dataset.
Create Nodes
In a graph database, nodes are fundamental components that represent entities or objects in the system. Each node usually has a unique identification and can be associated with various properties that describe its characteristics. Nodes are used to model and store relevant entity data. To create nodes, we can use Cypher queries. Here is an example of how to create a node to represent a person and merchant in the Credit Card graph database.
Create Person Node
- In the example above:
- CREATE: Used to create a new node.
- (:Person): Gives the newly created node the label "Person".
- {...}: Provides properties for the node.
This query creates a new Person node in the graph database with properties that include customer-related information such as name, gender and age.
Create Merchant Node
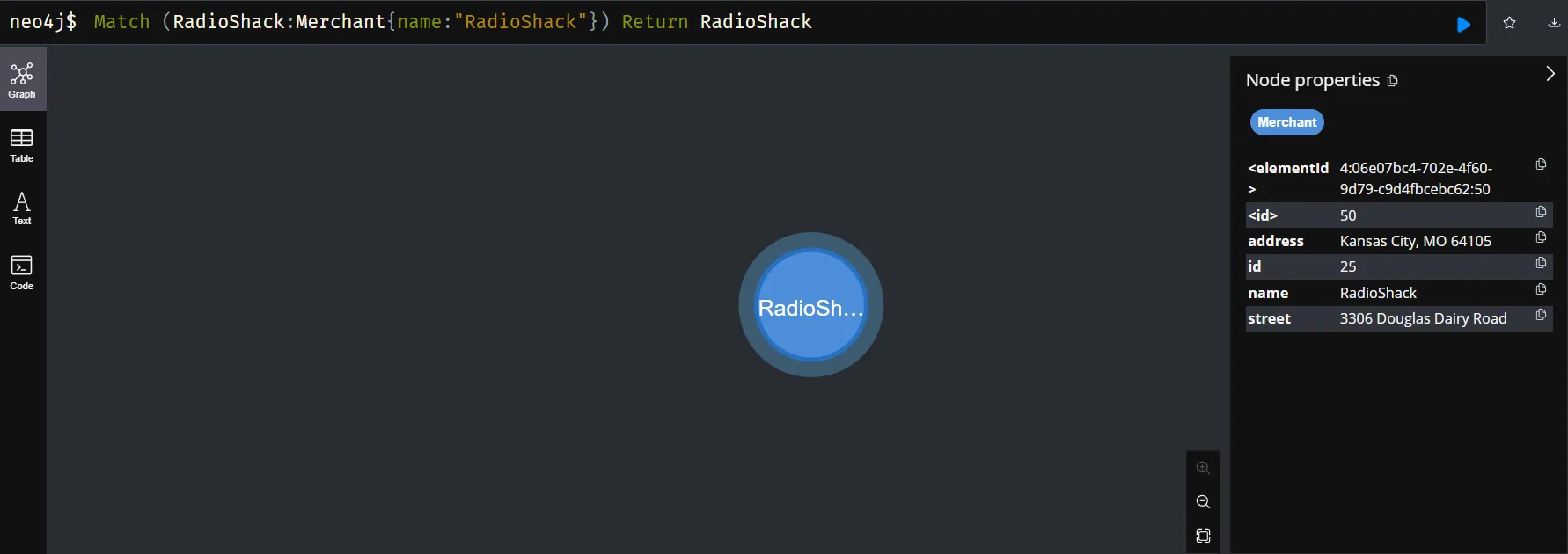
- In the example above:
- CREATE: Used to create a new node.
- (:Merchant): Gives the newly created node the label "Merchant".
- {...}: Provides properties for the node.
This query creates a new Merchant node in the graph database with properties that include place-related information such as name, street and address.
Create Relationships
Relationships in a graph database represent connections or associations between nodes. They are a fundamental component that allows modeling the relationships between different entities in a system. Relationships are used to capture meaningful interactions, dependencies, or associations between nodes. Here is an example of how to create a relationship between a person and merchant in the Credit Card graph database.
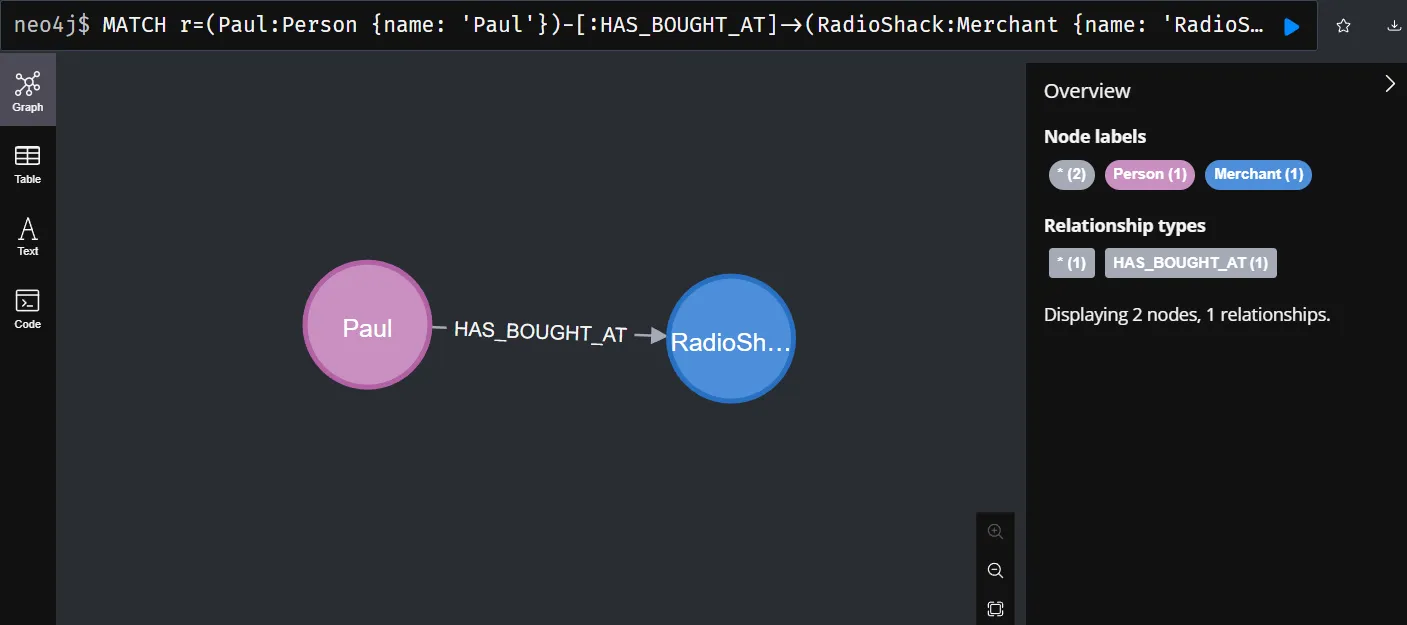
The given Cypher query aims to create a [:HAS_BOUGHT_AT] relationship between the Person node and the Merchant node.
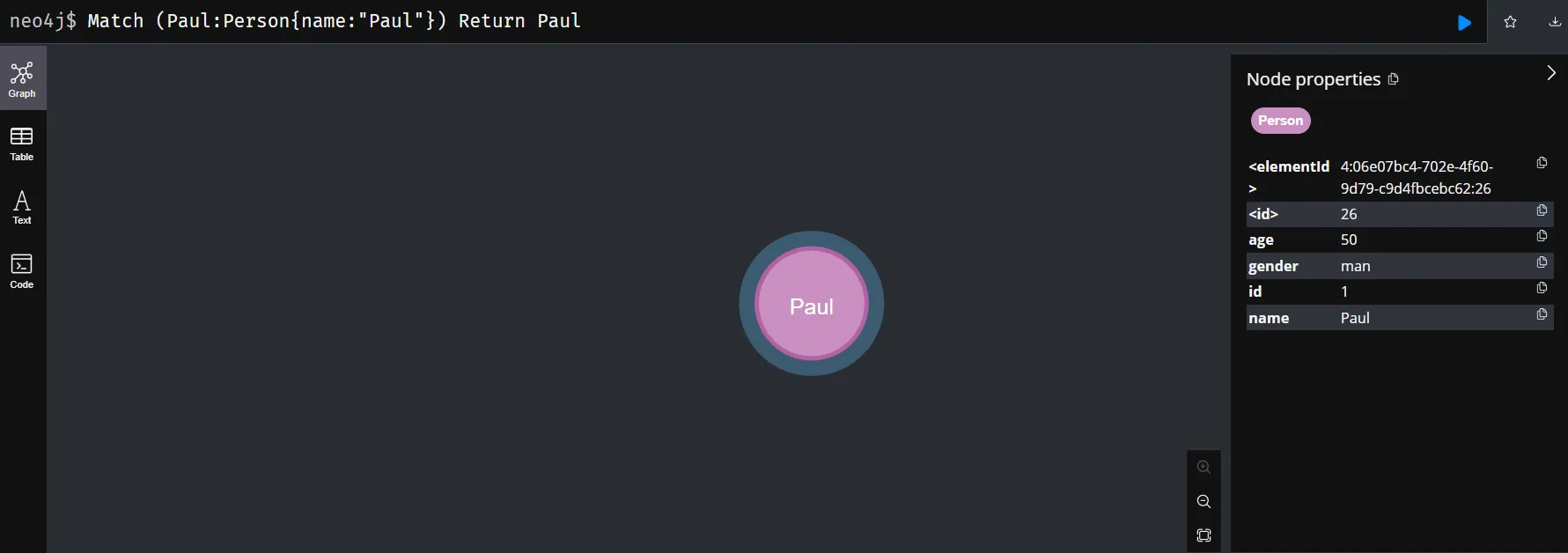
1. Matching the Existing Person Node:
Using MATCH to search for the person node with name 'Paul'. The customer variable is used to reference this Person node.
2. Matching the Existing Merchant Node:
Using MATCH to search for the customer node with name 'RadioShack. The order variable is used to reference this Merchant node.
3. Connects the Customer Node and Order Node:
Use CREATE to create a relationship of type [:HAS_BOUGHT_AT] between the Person node and the Merchant node. This relationship indicates that the customer has made a transaction from a specific merchant.
Executing this query will create a new relationship between the Person node and the Merchant node that matches the predefined matching conditions. This relationship will have a [:HAS_BOUGHT_AT] label, which provides the context that the customer has made a transaction at a specific merchant.
Fraud Detection and Result
Credit card fraud detection with a graph database utilizes the power of analyzing relationships between entities to identify suspicious transaction patterns. The graph database's ability to explore and interrogate relationships between data makes it a great choice for fraud detection. The following is how we can approach to detect a fraud:
- • Transaction Anomalies
Analysis of unusual transaction patterns such as an unusual number of transactions in a short period, purchases of suspicious value (too high or low), or purchase locations that are out of the customer's habit.
- • Customer Behavior
Observe customer purchase history to identify suspicious changes in behavior.
Queries
In detecting fraud, we need to first look for transactions that are considered suspicious. Unusual transaction activity can indicate the possibility of fraudulent activity. The following are the criteria selected as suspicious transactions:
- • High Average Transaction Amount (Purchases of Suspicious Value):
Transactions with a high average amount tend to feature unusual or unexpected large purchases. This can be a sign of fraudulent activity, such as purchasing high-value items using a stolen credit card or hacked account. In the query that will be created, we will set threshold of average transaction amount greater than 1500 USD. By choosing a high average transaction amount threshold, we can effectively check for unusual or unusual buying patterns that may indicate potentially fraudulent activity.
- • High Total Transaction Count (Unusual Number of Transactions in a Short Period):
In a relatively short period, a high total transaction amount for a given Person and Merchant combination could indicate fraudulent activity, such as a series of small purchases made repeatedly to avoid detection. In the query that will be created, we will set a threshold for the total number of transactions greater than 3. By choosing a high total transaction amount threshold, we can identify unusual or suspicious buying patterns that may be indicative of fraudulent activity.
The combination of these two criteria helps in identifying unusual or suspicious transaction patterns in the data, which may require further investigation to ascertain the legitimacy and validity of the transactions. By combining these two criteria, we can create a fraud detection system that is able to identify different types of suspicious transaction patterns and reduce the risk of financial losses caused by fraudulent activities.
Find Suspicious Transactions
The query above is intended to detect potential fraudulent activities in the transaction data. Here is the explanation of the query:
- 1. Match Transactions between People and Merchants
- 2. Calculate Statistics
- 3. Filter Transactions based on Average Amount or Transaction Count
- If the average transaction amount avgAmount is greater than 1500, or
- If the total number of transactions transactionCount is greater than 3.
- 4. Narrow Down to People with Potentially Fraudulent Transactions
- 5. Match Transactions Again and Filter based on Transaction Amount
- 6. Return Distinct Results
This line matches the pattern where the entity Person made a transaction HAS_BOUGHT_AT at Merchant. The variables used are p for Person, t for transaction relation, and m for Merchant. During this process, the query collects transaction data associated with each combination of Person and Merchant.
This query uses the WITH clause to pass the previous matching result to the next query. We calculate the average transaction amount avgAmount and the total number of transactions transactionCount for each combination of Person and Merchant. This helps us identify unusual transaction patterns, such as high transaction amounts or large average transaction amounts.
After collecting transaction statistics, the query sets criteria to identify transactions that are suspicious or potential fraud targets. Here, we apply the WHERE filter to evaluate the previous matching result based on the following criteria:
If the average number of transactions or the total number of transactions exceeds the threshold, these transactions are considered suspicious. These criteria help us identify transactions that are potential fraud targets due to high value or unusual number of transactions.
After applying the filter, we use WITH to pass only Person entities to the next step in the query.
We match the pattern where Person makes a transaction at the Merchant again, this time we only match transactions with an amount above or equal to 1000. We reuse the variables t for the transaction relation, and m for the Merchant. Transactions that meet the potential fraud criteria will be filtered, so that only transactions with amounts above or equal to 1000 will be retained. This helps to narrow the focus on transactions that have a significant financial impact, thus better detecting potential fraud.
Finally, we use the RETURN clause to return the final result of the query. We return the Person name p.name, Merchant name m.name, transaction amount t.amount and transaction time t.time. We use DISTINCT to ensure that only unique entities are returned, avoiding duplication in the output results.
Result
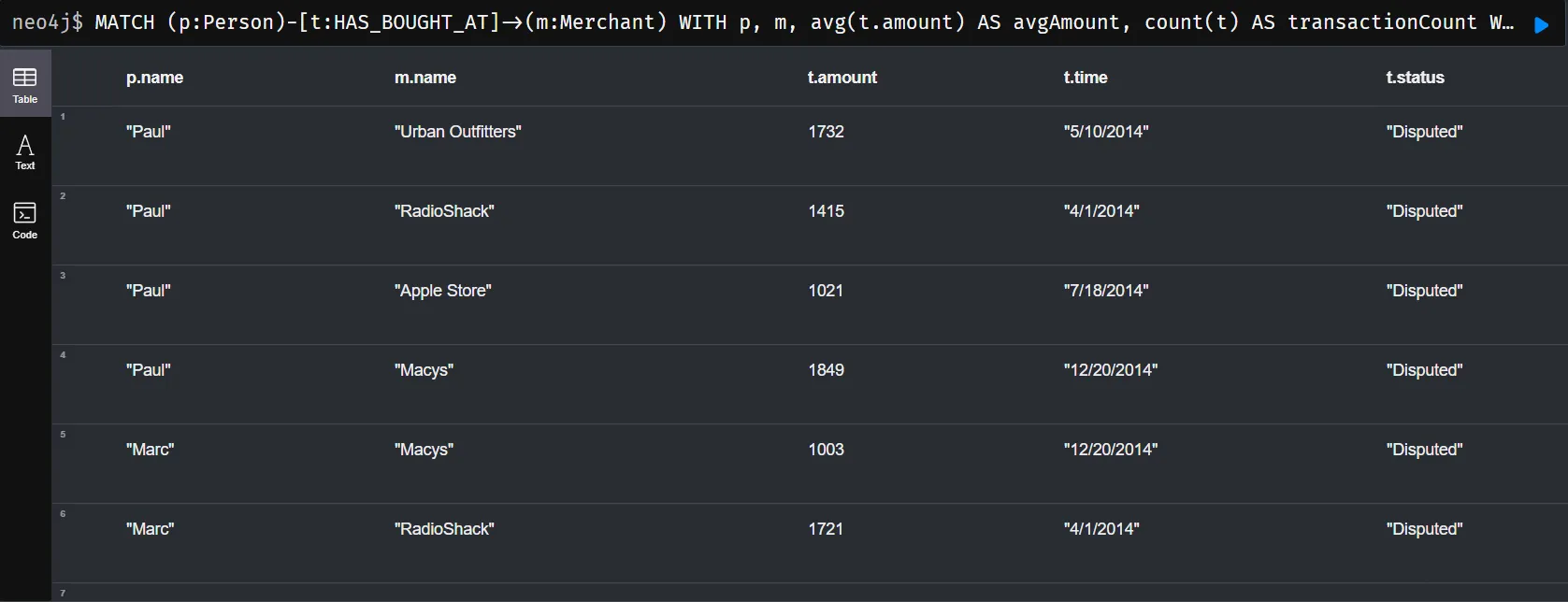
| Person | Merchant | Amount | Time |
|---|---|---|---|
| "Paul" | "Urban Outfitters" | 1732 | "5/10/2014" |
| "Paul" | "RadioShack" | 1415 | "4/1/2014" |
| "Paul" | "Apple Store" | 1021 | "7/18/2014" |
| "Paul" | "Macys" | 1849 | "12/20/2014" |
| "Marc" | "Macys" | 1003 | "12/20/2014" |
| "Marc" | "RadioShack" | 1721 | "4/1/2014" |
| "Marc" | "Urban Outfitters" | 1424 | "5/10/2014" |
| "Marc" | "Apple Store" | 1914 | "7/18/2014" |
| "Olivia" | "Macys" | 1790 | "12/20/2014" |
| "Olivia" | "Urban Outfitters" | 1152 | "8/10/2014" |
| "Olivia" | "Apple Store" | 1149 | "7/18/2014" |
| "Olivia" | "RadioShack" | 1884 | "8/1/2014" |
| "Madison" | "Macys" | 1816 | "12/20/2014" |
| "Madison" | "RadioShack" | 1368 | "7/1/2014" |
| "Madison" | "Apple Store" | 1925 | "7/18/2014" |
| "Madison" | "Urban Outfitters" | 1374 | "7/10/2014" |
From the query results, we can infer some insights related to the transactions patterns to detect fraud activities:
- • Large Amount Transactions
There are several transactions with high amounts, such as those made by Paul, Marc, Olivia, and Madison. These transactions with significant amounts can attract attention in fraud detection analysis due to the possibility of expensive or unusual purchases.
- • Unusual Transaction Patterns
Some transactions show unusual patterns, such as transactions occurring at several different merchants in a short period of time. An example is the transaction by Olivia at Macys, Urban Outfitters, and Apple Store on 7/18/2014.
- • Similar Transaction Patterns:
There are several transactions that have similar patterns between customers and the same merchant, such as those made by Marc at Macys, RadioShack, Urban Outfitters, and Apple Store. This may raise suspicion as to whether these transactions are the result of fraudulent activity or unauthorized coordination.
Although the query results show suspicious patterns, further analysis and investigation are needed to determine whether the transactions are actually cases of fraud or legitimate business activities. As such, the results of this query can be used as a starting point for further investigation in detecting and preventing fraudulent activities in business transactions.